
Data Cleaning | SQL
03 – 2023
En este proyecto se exploró la data de venta de casas de Nashville. El estudio se realizó en Microsoft SQL Server, y consistió en limpiar la base de datos con protocolo de estandarización, analizar dependencia entre columnas para identificar valores faltantes, así como el uso de expresiones regulares para separar columnas de datos agregados en columnas simplificadas.
La data se puede consultar en github.
A continuación, se ejemplifica una de las consultas realizadas.
SELECT *
FROM NashvilleHousing.dbo.NHousing
WHERE PropertyAddress is Null -- Recognize Nulls
ORDER BY ParcelID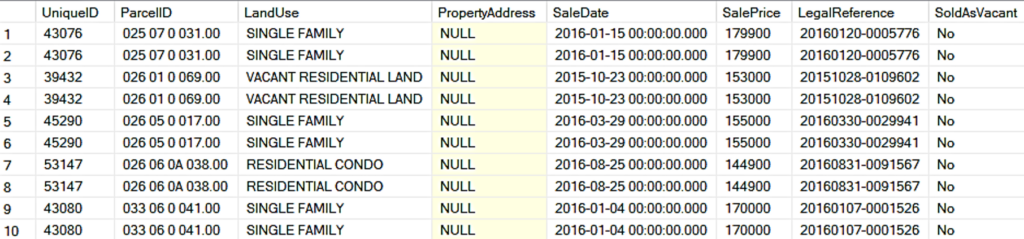
La consulta anterior fue para identificar las filas sin valor de PropertyAddress. Aunque la primera idea pueda ser desechar esas columnas, hay que revisar la posibilidad de exista información dependiente dentro de la base de datos. Hay que diferenciar entre asumir correlaciones, y el identificar relaciones de dependencia que suelan duplicar la información.
Notamos que PropertyAddress, está relacionado con ParcelID (el número de identificación del terreno). Si asumimos que esa identificación ParcelID no cambia, entonces se puede obtener el PropertyAddress de otras transacciones (UniqueID) asociadas al mismo ParcelID.
De esta forma, realizamos otra consulta en la que unimos la tabla de datos consigo misma. Esto con el fin de tener en una misma fila la información de un terreno (ParcelID), pero con diferentes transacciones (UniqueID).
SELECT a.ParcelID, a.PropertyAddress, b.ParcelID, b.PropertyAddress, ISNULL(a.PropertyAddress, b.PropertyAddress) -- a.PropertyAddress will be replaced by ISNULL
FROM NashvilleHousing.dbo.NHousing a
JOIN NashvilleHousing.dbo.NHousing b
on a.ParcelID = b.ParcelID -- Identificacion de Terreno
AND a.[UniqueID] <> b.[UniqueID] -- Different Sale // Transacciones diferentes
WHERE a.PropertyAddress is Null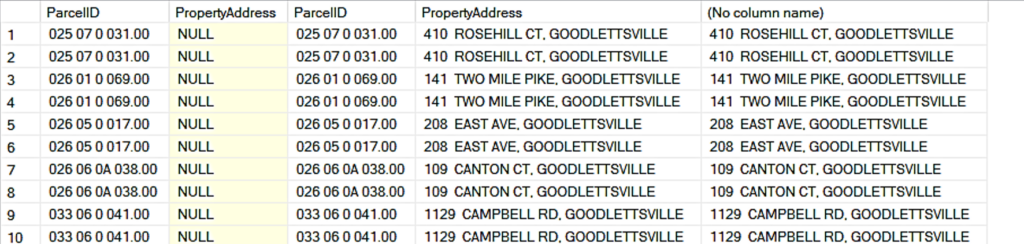
Notamos la misma ParcelID de un PropertyAddress nulo resulto asociada otra transacción donde si se reportó el PropertyAddress. De tal manera, que podemos rellenar esa información sin despreciar esas filas de valores nulos. Esto se hace con ISNULL, para indicar que se quede el valor no nulo de las dos columnas de PropertyAddress.
UPDATE a
SET PropertyAddress = ISNULL(a.PropertyAddress, b.PropertyAddress)
FROM NashvilleHousing.dbo.NHousing a
JOIN NashvilleHousing.dbo.NHousing b
on a.ParcelID = b.ParcelID
AND a.[UniqueID] <> b.[UniqueID]
WHERE a.PropertyAddress is Null
SELECT *
FROM NashvilleHousing.dbo.NHousing
WHERE PropertyAddress is Null -- Dont have Nulls
Finalmente, se realizó una consulta para verificar los valores nulos de PropertyAddress. Se puede notar que la consulta no dio ninguna fila, lo que significa que ya no hay valores nulos para la columna PropertyAddress.
A continuación, puedes revisar todas las consultas realizadas.