
Data Analysis | Python
04 – 2023
En este proyecto se analizaron los datos de 7668 películas, que datan desde 1986 hasta 2019. Los datos fueron limpiados y validados para llevar a cabo un análisis en el que se identificaron valores atípicos, y se estudió la correlación y la contingencia entre las variables numéricas y categóricas.
La data (movies.csv) puede ser descargada en kaggle.
Se trabajó en un Jupyter Notebook, iniciando con explorar la data.
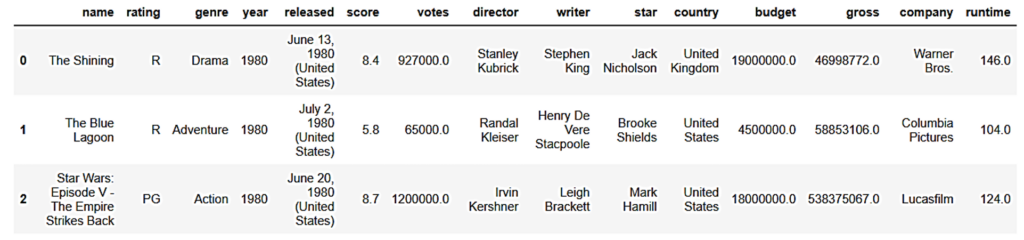
Data Cleaning
La limpieza de datos comenzó analizando los Valores Nulos.
# de Filas : 7668
+----------+---------+------------+
| Columna | # Nulls | % de Nulls |
+----------+---------+------------+
| rating | 77 | 1.0 |
| released | 2 | 0.03 |
| score | 3 | 0.04 |
| votes | 3 | 0.04 |
| writer | 3 | 0.04 |
| star | 1 | 0.01 |
| country | 3 | 0.04 |
| budget | 2171 | 28.31 |
| gross | 189 | 2.46 |
| company | 17 | 0.22 |
| runtime | 4 | 0.05 |
+----------+---------+------------+Se evitó inicialmente eliminar los valores nulos de presupuesto (budget) e ingresos (gross) por ser estadísticamente significativos. El no eliminar esas filas puede brindar información estadística relevante para los análisis de las demás columnas.
También se analizó la dependencia de la data entre released con year y country. La cual puede ser útil para rellenar valores faltantes debido a la duplicidad de la información en otra columna.
Por ejemplo, se usaron expresiones regulares para simplificar y validar la nueva columna de year_released. La ausencia de números permitió ubicar los errores.
# de errores: 46
con los distintos inputs:
6413 States)
1947 (United
5833 (Australia)Al revisar la información completa, fue posible identificar porque ocurrieron esos errores al construir la columna year_released. Ya que se construyó rompiendo las cadenas de texto en subcadenas a partir del espacio, e identificando el número de subcadena del año. En estas filas hubo error debido a que no tenían día o mes, lo que modifica el índice del año entre las subcadenas.
6413 2013 (United States)
1947 February 1992 (United States)
5833 November 2010 (Australia)Para finalizar la limpieza de datos, se corrigió los tipos de datos y se hizo una revisión por duplicados.
Data Analysis
Para empezar el análisis de datos se partió con la exploración de valores atípicos. Podría ser un análisis propio de la limpieza de datos, sin embargo, en este caso no se buscaba quitar de la data valores erróneos. Si no revisar los valores más estadísticamente atípicos.
No se comienza aplicando un filtro debido a que estos aplican criterios estandarizados para distribuciones normales. Por lo cual se comenzó con revisar cual es la distribución que se forma de los ingresos brutos (gross). Se determinó que la Distribución No es Normal, como se ve en la siguiente gráfica. Por lo que se requiere aplicar una transformación Box-Cox que normalice la distribución.
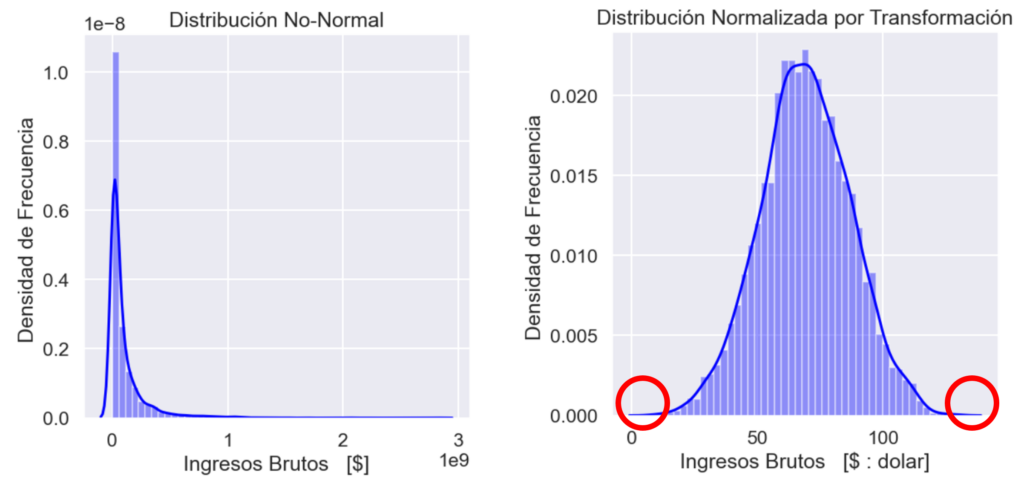
Una vez que se tiene la distribución normalizada, se puede aplicar un filtro estandarizado para identificar los valores atípicos. Se notó además que el filtro Quantile (y también pasa con el z-score) no presentan cambios debido a la transformación. Esto se debe a que son filtros que operan sobre orden de los datos, independientemente de sus valores. Algo que no ocurre con el filtro IQR, el cual, si considera distancias dentro de su cálculo, por lo que este filtro no mostró tanto sesgo como el filtro Quantile. De tal manera que, con la normalización, el método de IQR pasó de filtrar 555 valores como datos atípicos, a sólo 12 valores.
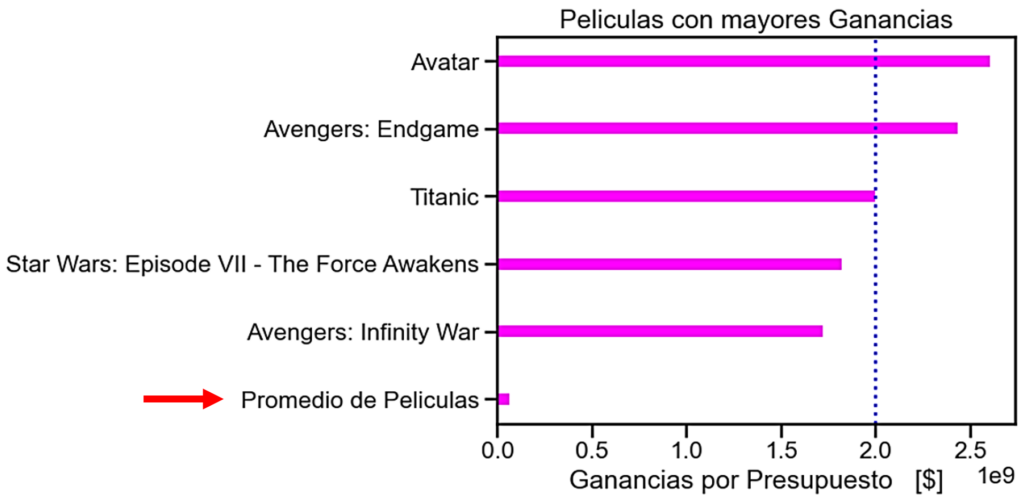
Las 5 películas atípicas con mayores ingresos se muestran a continuación. Se visualizan los Ingresos menos el presupuesto de esas películas, donde se nota la enorme diferencia de esos valores con el Promedio de las Películas.
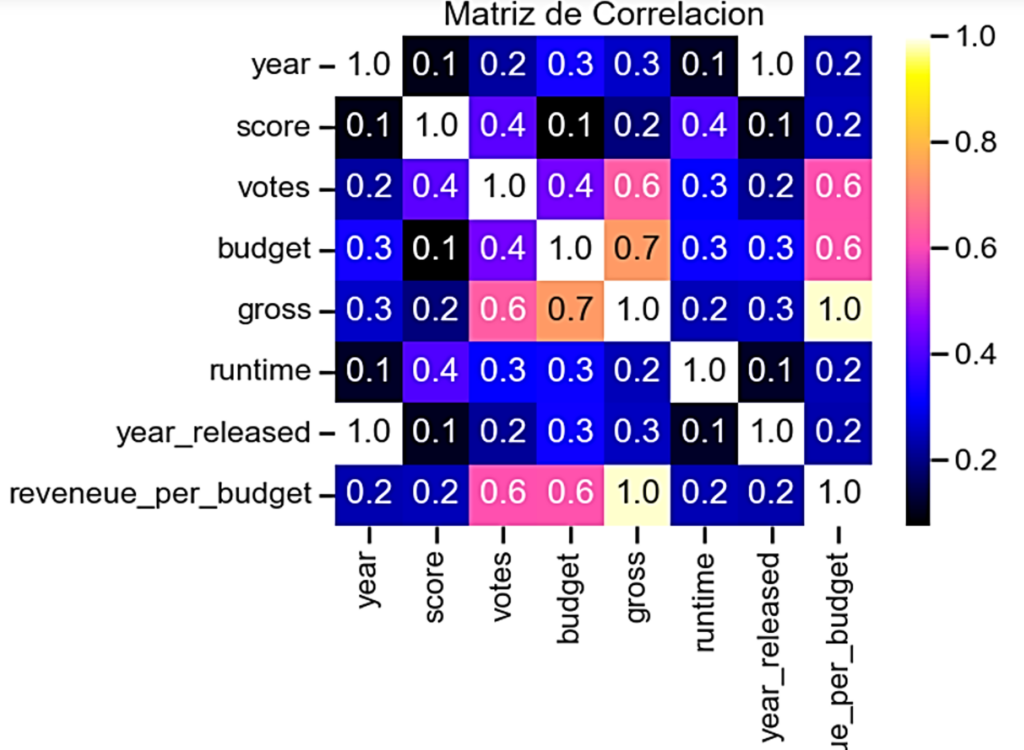
Se prosiguió con un análisis de correlación. Donde se identificó que presupuesto (budget) e ingresos (gross), y votos (votes) e ingresos (gross) son las variables que muestran mayor correlación entre ellas. Por lo que se aplicó un método de regresión.
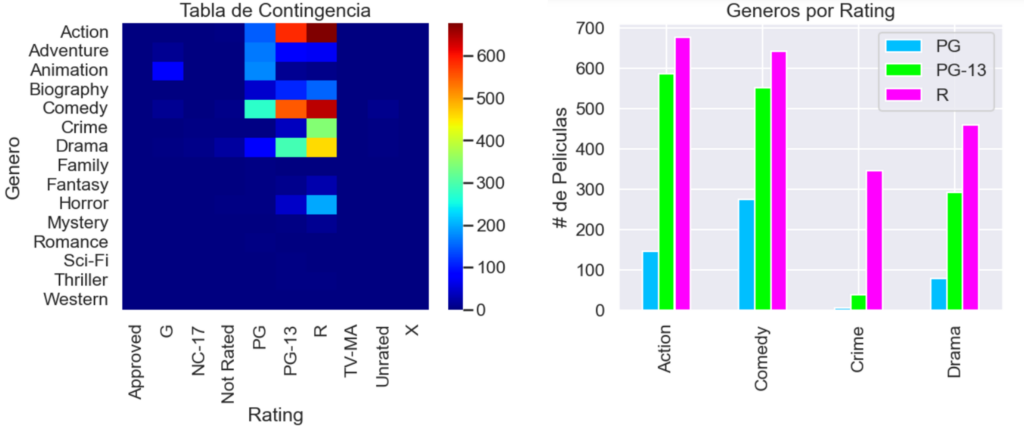
Se siguió con un análisis de las variables categóricas. No se hizo un proceso de codificación, debido a que no se buscaba establecer métricas de distancia entre conjuntos. Por lo cual, se prefirió utilizar una tabla de contingencia (crosstab) para analizar el acoplamiento de las modas (o modos) de las variables.
Para este análisis nos centramos en las variables género (genre) y rating. Las coincidencias en frecuencia (cantidad de películas) fueron relevantes sólo para los géneros de acción, comedia, crimen y drama, y para las clasificaciones de PG, PG-13 y R. Por lo que se optó por filtrar para visualizar sólo los datos más relevantes. Tal que notamos que, en esos 4 géneros, la moda es realizar películas de clasificación R.
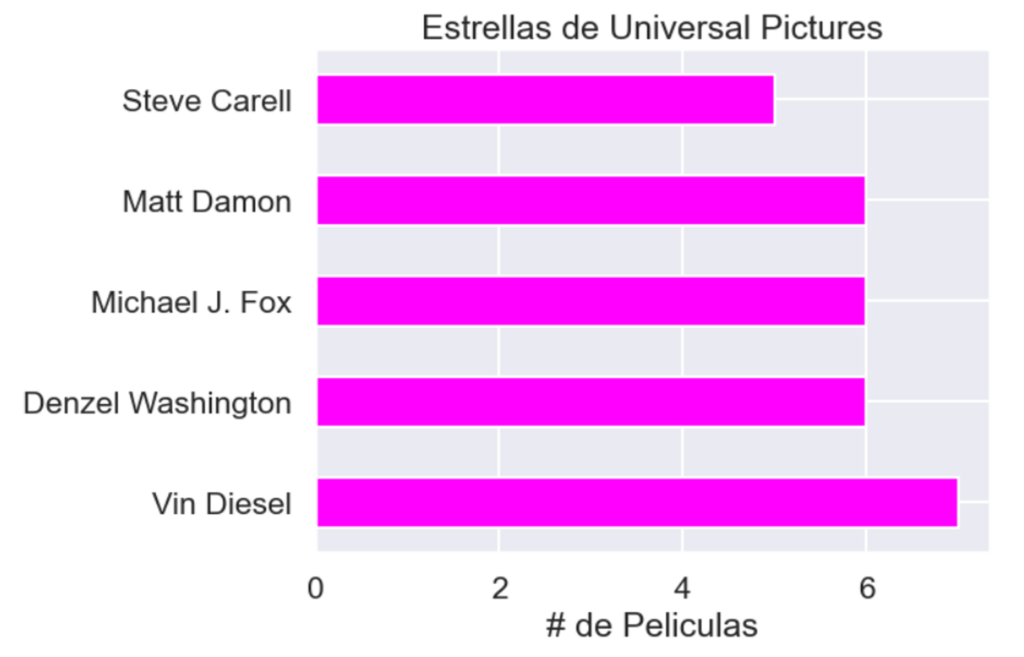
Se exploró el modo de la columna Companies. De este, se identificó que el estudio (no conglomerado) con mayor cantidad de producciones era Universal Pictures. De ahí se buscó analizar cuáles son las estrellas más relevantes de este estudio.
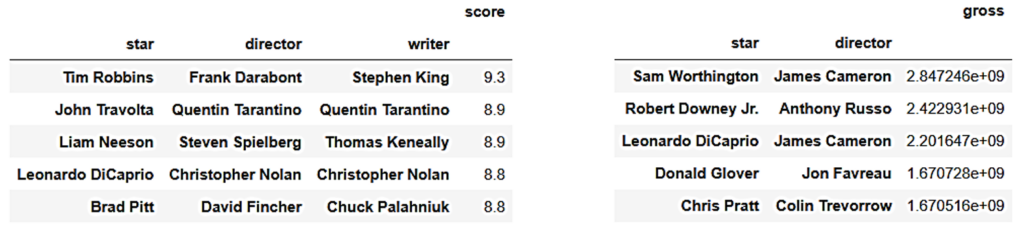
Finalmente, ya se realizó un análisis conjunto de variables numéricas con variables categóricas.
Por lo que se propuso analizar cuáles son los grupos de estrella, director y escritor que obtienen de media las puntuaciones más altas en IMDb y los ingresos en taquilla más altos en sus películas.
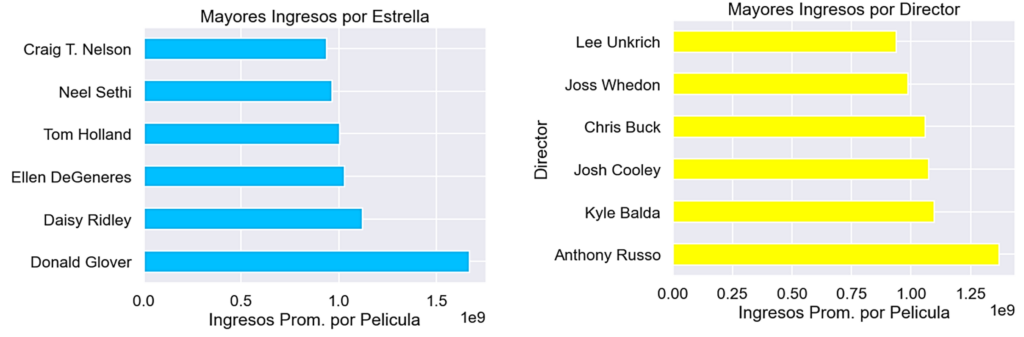
Para verificar si un integrante de esos grupos es más relevante, se exploró a las estrellas y directores respecto a los ingresos por película que suelen obtener en sus producciones. Así, se identifica que Donald Glover y Anthony Russo suelen tener buenos resultados también de forma independiente.
A continuación, puedes consultar el código del proyecto.